Event-driven Live-streaming Recommender System
This article is a translated version of my article posted on Hyperconnect Tech Blog, originally written in Korean. 한국어 포스트를 보시려면 위 링크를 클릭해주세요.
We face various engineering challenges when applying machine learning technologies to products. This article introduces the challenges we have encountered while building a Live-streaming recommender system applied in Azar Live and Hakuna Live, the live-streaming platforms of Hyperconnect.
Recommender System on Live-streaming
The goal of the recommender system is to find a few items that the user will like among many items of the service. Item is mostly determined by the domain, for example, product on Amazon, movie or video on Netflix, and music on Spotify. In the “Live-streaming” domain, the item becomes “Streamer” or “Live Broadcast”. Therefore, the live-streaming recommender system should aim to recommend the streamers or live broadcasts that users will like the most.
 Figure 1. Hakuna Live and Azar Live
Figure 1. Hakuna Live and Azar Live
However, the streamer item is quite tricky in the recommender system, since it has the following two characteristics.
1. We should only recommend streamers who are currently broadcasting
If we recommend clothes, food, movies, or music, we don’t need to consider whether they are online or not. In contrast, in a live-streaming recommender system, we need to know which streamer is currently live-streaming [1].
2. Model should utilize real-time data because context changes frequently
In the case of clothes, food, movies, and music, they always exist in the same state as yesterday or today, and the person who saw the movie a week ago and the person who saw it yesterday will not be much different. However, in live-streaming, the broadcast content of the streamer may vary depending on the time (the difference between morning broadcast, afternoon broadcast, and dawn broadcast), and characteristics may change due to special events during the broadcast (for example, a celebrity guest will appear occasionally). Therefore, it is important to use real-time data in the model.
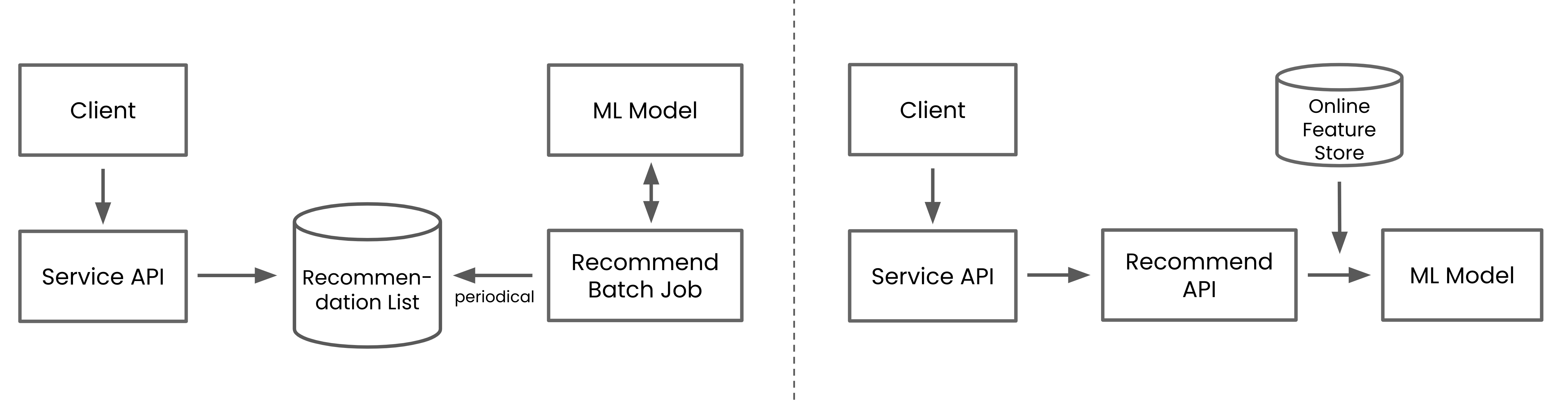 Figure 2. The recommender system that operates in non-real-time based on the recommendation DB (left), and the system that operates in real-time through the recommendation API (right)
Figure 2. The recommender system that operates in non-real-time based on the recommendation DB (left), and the system that operates in real-time through the recommendation API (right)
While real-time is important in the live-streaming domain, using real-time context in a recommender system requires more engineering challenges. For example, in a recommender system where real-time is not important, the system can be implemented with a recurring batch job - that calculates a recommendation list and stores the list in the database - and simple API server - that reads the pre-calculated recommendation list from the database.
However, in a recommender system where real-time is important, the model should be inferred in real-item every time a user requests a recommendation list. The real-time model inference is not an easy task because additional engineering tasks are required to infer the model, such as retrieving the model input features in real-time. These tasks complicate the backend system for recommendations.
To efficiently develop and operate a high-complexity recommender system, Hyperconnect has developed a recommendation backend system with microservice architecture (MSA) and event-driven architecture (EDA). With MSA and EDA, we have built a highly scalable and low coupled system, and we are able to use more diverse real-time features, which are especially important in a live-streaming recommender system. Also, the development and deployment of the recommender system can be done independently from the other backend services. In the next section, I’ll explain the two architectures applied to the recommender system of Hyperconnect.
Microservice Architecture and Event-driven Arcitecture
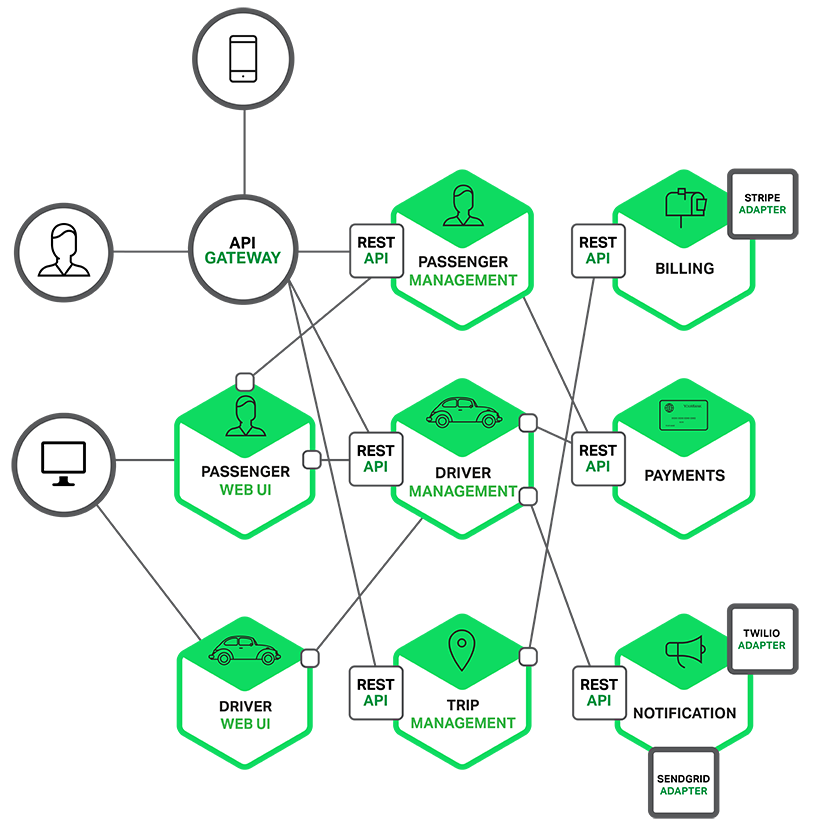 Figure 3. Microservice Architecture (MSA). Source: nginx.com
Figure 3. Microservice Architecture (MSA). Source: nginx.com
Microservice Architecture
Microservices architecture (MSA) is an architecture and approach to developing large, complex software by breaking it down into smaller, independent modules [2]. The biggest advantage of applying MSA is that the distribution cycle is shortened. In particular, the effectiveness of MSA is maximized as the organizations participate for one product grows. Hyperconnect’s recommendation microservices are also decoupled from the product microservices. It is more efficient to let the product development team focus on the core features of the product, and the recommendation team focuses only on the recommendations.
However, even if MSA is used, deployment cycle might slow down again if API requests between microservices become frequent or a shared database starts to appear. In this case, the low coupling, which was originally an advantage of MSA, can be gradually broken and communication costs increase.
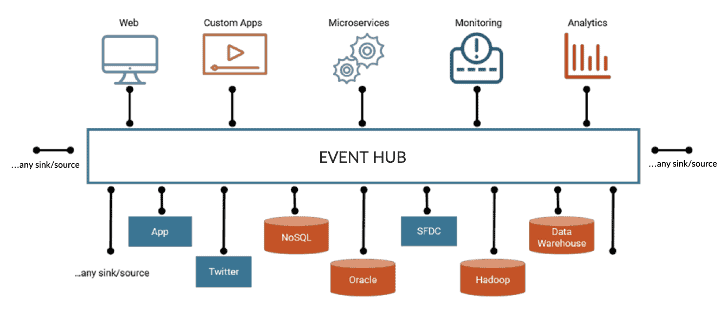 Figure 4. Event-driven Architecture (EDA). Source: anexinet.com
Figure 4. Event-driven Architecture (EDA). Source: anexinet.com
Event-driven Architecture
In this situation, one of the ways to lower the coupling between microservices is to adopt event-driven architecture (EDA). Microservices and event-driven architectures are collectively referred as Event-driven Microservices. In the EDA, when an API call or transaction occurs, the microservice that handles the transaction publishes an event to a common event bus (ex. Kafka), and other microservices that need the event subscribe to the event [3]. Organizing the system with an event-driven architecture makes the flow of data clearer, simplifies the communication scenarios between microservices, and eventually makes the loosely coupled system [4].
Hyperconnect has already developed various products and features with event-driven architectures, and machine learning-based service development is not an exception. The event-based system has the disadvantage of slightly increasing the engineering cost, but it has the advantage in that it allows development with a high degree of freedom while minimizing the communication cost.
Event-driven Live-streaming Recommender System
It is clear that developing a recommender system as a microservice separated from the other services allows accelerating development, deployment, and experiment cycle through reducing the communication cost. Yet, how does event-driven architecture specifically help in building recommender systems? Let’s take an example for retrieving the model input features required for recommendation model inference.
Let’s assume that we use input features such as number of current viewers per live-room or average watch time in the recommendation model. At this time, to get current viewers per live-room or average watch time from a microservice which is NOT implemented with event-driven architecture, one of the two methods below should be used.
- Request to the product backend team to develop an API that returns the data
- Create a shared database used by multiple microservices
At the first iteration of the service development, the above methods may be fine. However, as time goes by, both methods can degrade productivity and even reduce recommendation performance, because they have the following problems.
Problem of requesting to the product backend team to develop an API
In this method, we cannot use the data immediately because we should wait until the product team develops an API. And, there may be many communication overheads with multiple meetings while developing and deploying the API. Consequently, this method reduces productivity and even reduces the opportunity to experiment new recommender models online.
Problem of the shared database used by multiple microservices
This method is also not an option worth considering. In this architecture, we have to carefully use the database. For example, a write operation can affect the performance of other APIs, thus we may need to consider the all side-effects of the write operation before starting development. And in this case, communication costs are also increased again.
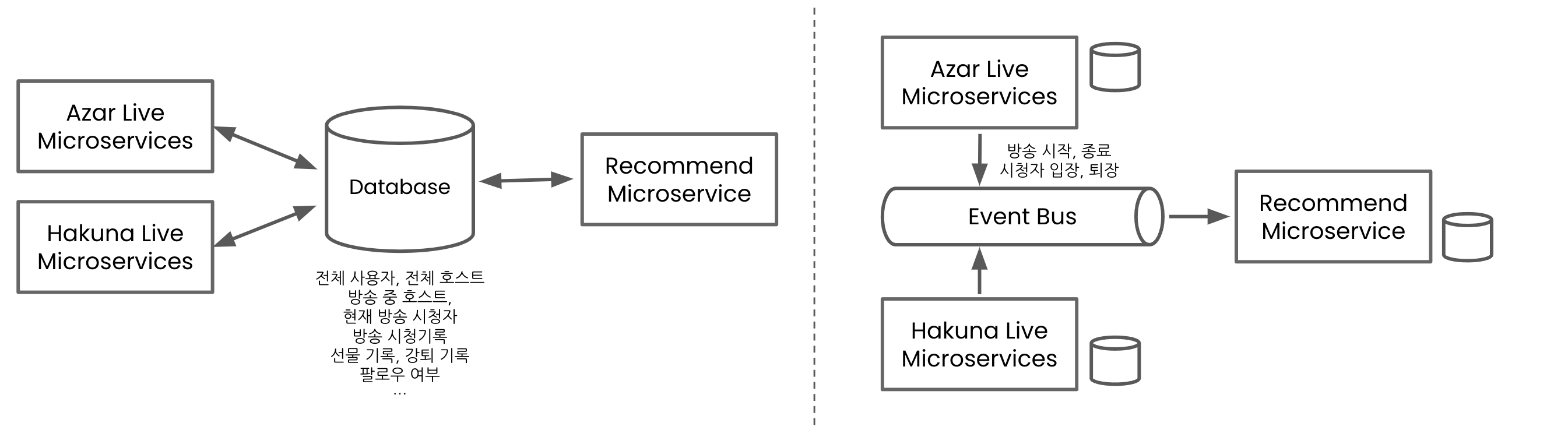 Figure 5. Shared database-based MSA (left), Event-based MSA (right)
Figure 5. Shared database-based MSA (left), Event-based MSA (right)
Event-driven Architecture
Event-driven architecture solves those problems. In EDA, product backend services such as Azar Live or Hakuna Live, publish live-streaming watch events to the event bus like Kafka, and the recommendation service subscribes the events. To calculate number of current viewers per live-room or average watch time in recommendation service, we can calculate them by using the live-streaming watch events! It is easy and simple.
As an event doesn’t often change once the specs are set, communication cost is not increased much later. In addition, a scalable system can be built naturally, and the service can be operated stably because single point of failure[5] is reduced. Best of all, building a recommender system based on events will give us a lot of freedom and speed up the new model experiment cycle. How? If we need a new feature, just pull the events and calculate the features from the events! It’s done.
Live-streaming Recommender System of Hyperconnect
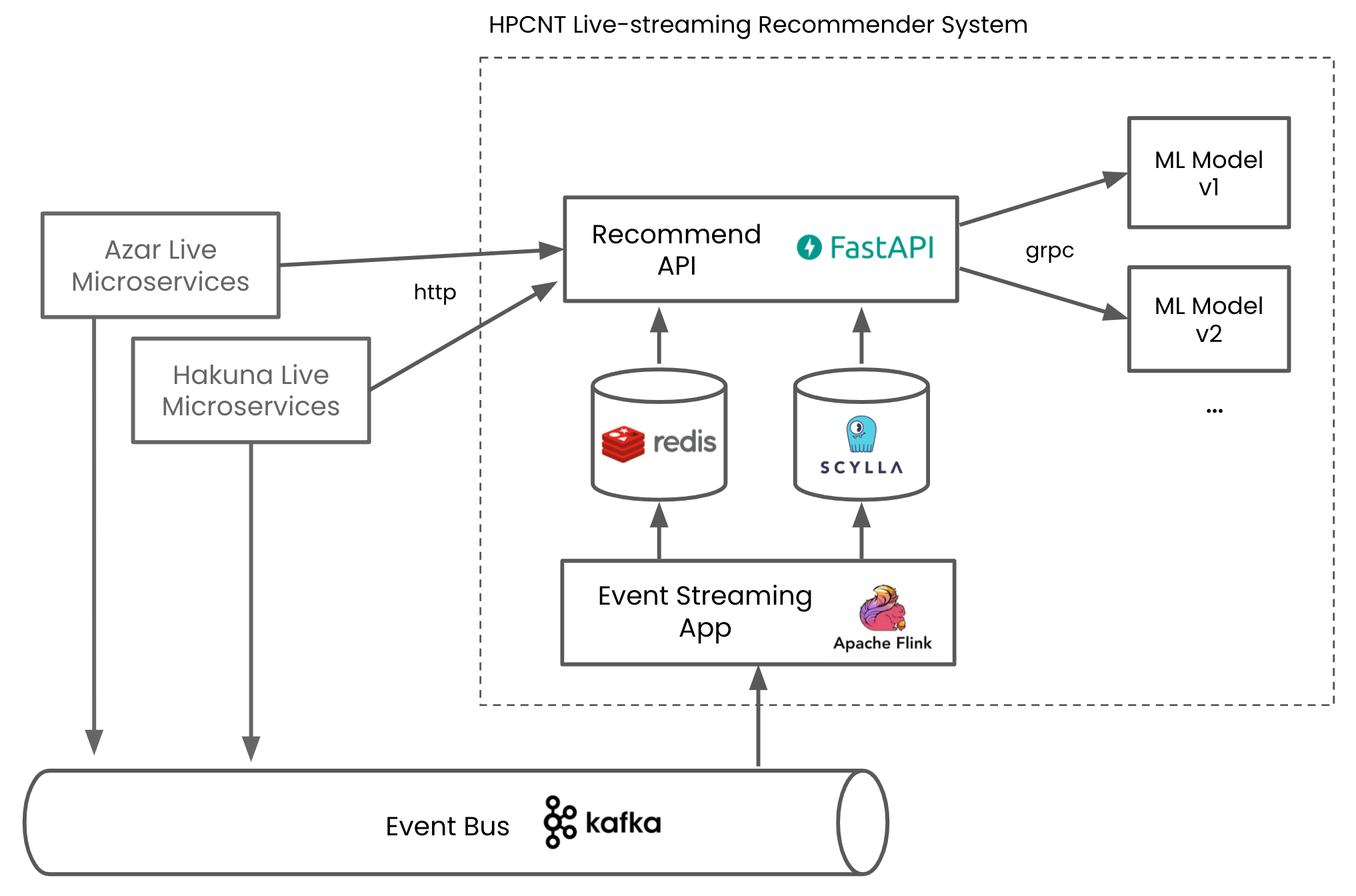 Figure 6. Live-streaming Recommender System of Hyperconnect
Figure 6. Live-streaming Recommender System of Hyperconnect
Hyperconnect’s live-streaming recommender system is developed with an event-driven architecture. There is no dependency on other microservices, and data is managed only by events received through Kafka. With EDA, we are able to experiment with new models with new data easily, because we can implement the new data calculation logic by processing existing events without extra communication with other organizations.
Generally, it is easy to think that the performance of the model is the most important in the machine learning system. Of course, in practice, the model is very important. However, in a recommender system that frequently exchanges real-time data, such as live-streaming, the system architecture also affects the recommendation performance. Even if the most accurate machine learning model is created in the research phase, the model might not be used in production if the system cannot calculate the real-time features which are required in the model inference. Or, if the development speed of the serving-side is slower than the model research speed, the iteration will inevitably be slow, and the opportunity for higher performance improvement may be wasted. To run the cycle of hypothesis → offline experiment → online experiment → improvement → hypothesis, which is the most important in machine learning, it is necessary to show sufficiently high productivity even in the ML backend systems.
Event-driven architecture ensures development independence and reduces productivity degradation due to the cost of inter-organizational communication as the system grows. This allows for rapid development and deployment even as the system matures and code becomes more complex, and allows for frequent model experimentation and improvement cycles.
Engineering Challenges on the Implementation
Although we have shown that event-driven architectures is effective in recommender systems, event-driven architectures are not a silver bullet. Real-time recommender system still has many engineering challenges in the implementation stage, and in this section, we will briefly introduce representative challenges we encountered.
1. Should handle the events in real-time, such as streaming start/end, viewer entrance/exit
To solve the problem of processing events in real-time, we use Apache Flink to process events asynchronously. Flink is a framework that allows processing data in real-time by subscribing events from an event bus such as Kafka. With Flink App, we synchronize a database for recommendation API servers, such as user profile DB and online status DB. Further, we calculate and store feature values in the in-memory store required for model inference. By using Flink, we are able to produce many data used in recommendation server easily and efficiently.
2. Should calculate input features for model inference in near real-time
The computational time of model input features can be an issue. If you adhocly calculate the input features for model inference every time a user requests the recommendation list, it takes a long time to load and process data, which can slow down the response time. Instead, we use the Flink App to pre-compute features that take a long time to compute asynchronously. In other words, we pre-compute features when an event is issued, not when an API request is made. By asynchronously calculating the features, requests for recommendation lists containing hundreds of items are handled in tens to hundreds of milliseconds even if our recommendation models use more than hundreds of features.
3. Should infer various machine learning models
The challenge of inferring multiple machine learning models in real-time is solved through our in-house ML Serving Platform. Hyperconnect operates an in-house ML Serving Platform based on the many years of experiences of MLOps, and we can deploy a new machine learning model really quickly. ML Models are deployed as Kubernetes pods and set to auto-scaled. Also, we adopt technologies such as Nvidia Triton to provide high throughput and low latency.
4. Should be scalable
Recommendation API server and the Flink App are written stateless to guarantee scalability. Also, they are deployed as Kubernetes pods and are set to auto-scaled. The database has also sufficiently scalable as we use Redis and ScyllaDB, which are designed as a scalable key-value store and distributed NOSQL database, respectively. All other components are designed to be scalable, including machine learning models.
Conclusion
In this article, I introduced the effect of event-driven architecture in a live-streaming recommender system. I also showed various engineering challenges and solutions we encountered while developing a live-streaming recommender system. However, other than the above problems, there are many more difficulties when operating an event-based recommender system. For example, in event-based applications, the order of event processing might be an issue since event-consuming time and event issuing time might be different. Developing a fault-tolerant system is another concern in event-streaming pipelines. Sometimes, due to the differences in the implementation of the feature calculation logic, there may be a problem in that the online features on the serving-side and the offline features on the training-side may be different [6]. To solve this problem, we may need to consider components such as a feature distribution analyzer, shared feature encoder, or feature store. And while adopting these components, we face new challenges.
Various challenges exist from a modeling perspective as well. For example, how to accelerate the deployment cycle of the model is one of the most important concerns. How to increase the accuracy in the online environment beyond offline accuracy is also a big challenge.
When you apply machine learning to production, you run into a lot of different problems. Instead of optimal solutions to the problems, we solve the problems in efficient methods suitable for each situation. We believe that engineers who can quickly define problems and suggest solutions can have an impact on business through machine learning.
References
[1] R, Jérémie, et al. “Recommendation on Live-Streaming Platforms: Dynamic Availability and Repeat Consumption.” RecSys 2021.
[2] https://www.redhat.com/en/topics/microservices
[3] https://medium.com/dtevangelist/event-driven-microservice-란-54b4eaf7cc4a
[4] https://medium.com/trendyol-tech/event-driven-microservice-architecture-91f80ceaa21e
[5] https://en.wikipedia.org/wiki/Single_point_of_failure
[6] https://engineering.atspotify.com/2021/11/15/the-rise-and-lessons-learned-of-ml-models-to-personalize-content-on-home-part-i/