AI 연구 조직에서의 SWE 인턴기
얼마 전 N사의 C모 AI 연구 조직에서 Software Engineering(SWE) 인턴을 3개월간 진행했다. 특히 내가 있었던 팀은 회사 내에서도 개발보다는 연구에 치우쳐져 있는 조직이었는데, 구체적으로는 팀원분들이 모두 박사학위를 소지하고 있는 연구 중심적인 팀이었다. 처음 이 팀에 들어가게 된 이후 이런 팀에 엔지니어 인력이 왜 필요한지, 또 엔지니어로서 팀에 기여할 수 있는 부분이 무엇이 있는지 정말 고민을 많이 했었다. 특히 조직 문화가 시키는 일만 따박따박 하기보단 스스로 할 일을 찾고 제안하는 분위기였기에, 인턴 기간 동안 내가 할 수 있는 것을 잘 찾아야만 의미 있는 아웃풋을 낼 수 있으리라 생각했다.
그리고 결과부터 말하자면, 목표 설정과 함께 내가 팀에 기여할 수 있는 부분을 빠른 시간 내에 잘 찾아낼 수 있었고, 3개월이라는 비교적 짧은 시간 동안 크게 3가지의 꼭지로 조직에 기여할 수 있었다.

Task 1: AI 연구자를 위한 사내 Web Service 개발
Machine Learning의 결과는 보통 모델이라 불리는 파일로 저장된다. 모델 파일에는 주로 다수의 가중치 행렬weight matrix이 저장되어 있으며, 모델을 불러옴으로써 중단된 학습training을 계속하거나 추론inference에 사용할 수 있다. 보통 모델 학습에 수 시간~수 일씩 소요되기 때문에 모델 파일을 잘 관리할 수 있다면 중복된 학습 작업을 줄일 수 있게 된다. 특히 최근에는 모델의 학습이 한 번에 끝나지 않고 Transfer Learning 이나 Finetuning 처럼 1차 모델을 학습시킨 후 해당 모델을 바탕으로 2차 모델을 학습시키는 식으로 진행되기 때문에, 모델 파일에 대한 관리는 중요해져 가고 있다고 볼 수 있다.
이러한 배경을 가지고 내가 이 팀에서 개발한 Web Service는 Machine Learning 모델을 저장하고 관리할 수 있는 사내 서비스다. 기존의 CLI 형태로 모델 파일에 대한 업로드/다운로드를 진행할 수 있게끔 만들어져 있는 라이브러리를 커스터마이징하고 웹 서비스 형태를 추가적으로 개발하는 작업을 인턴 기간 중 가장 먼저 진행하였다.
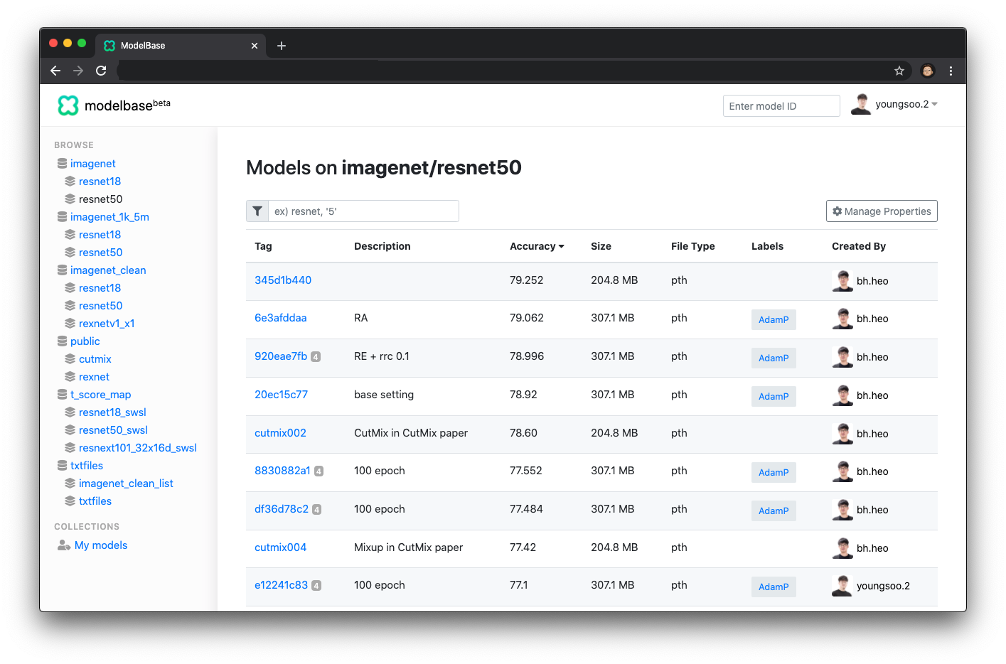
사용했던 기술 스택은 아래와 같다. 기능 자체가 많지 않았기에 백엔드와 프론트엔드 모두 혼자 개발을 진행했다.
- 프론트엔드: TypeScript / React
- 백엔드: Python / Flask
- 데이터베이스: MongoDB (기존 코드 참고)
- 스토리지: 사내 스토리지 서비스 (기존 코드 참고)
- 인증: Github OAuth App / JWT
기본적으로 모델의 업로드, 다운로드, 수정, 삭제 기능을 제공하며, 특히 단순한 저장소 기능을 넘어서 모델을 일종의 자산으로서 관리할 수 있도록 서비스를 개발했다. 서비스를 개발하며 몇 가지 정책을 새로 만들었고, 사내 ML 코드와 연동하여 자동으로 모델을 업로드하고 불러오는 로직 또한 개발했다. 웹 어플리케이션에서의 대표적인 기능으로는 1) 여러 모델 간의 비교가 가능하며, 2) training args로 모델의 검색/정렬, 3) 모델 공유를 위한 기능 등이 탑재되어 있다.
0) Hash 기반 모델 ID
기본적으로 내가 개발하게 된 서비스는 사내에서 연구용으로 사용되는 제품이다. TensorFlow Hub 처럼 외부 공개를 목적으로 만들어진 서비스라면 큰 상관은 없겠지만, 내부용으로 사용되는 서비스는 누구나 그렇듯 관리에 큰 시간을 들이고 싶어 하지 않는다. 이는 특히 모델의 명명, 혹은 태깅에서 문제가 될 것으로 예상했는데, 모델의 이름을 모두가 대충 정해 temp, temp2 같은 이름의 모델만 수십 개가 될 것 같은 느낌이 들었다.
이 문제를 회피하고자 비교적 파격적(?)인 정책을 제안했는데, 모델의 training args를 hashing 한 결과를 모델 ID로 사용하자는 것이었다. 예를 들면 모델의 이름이 3c7039714이 되는 것이다. 하지만 이는 너무 가독성이 떨어지니 모델을 표현하는 대표적인 두 정보 ‘데이터셋’과 ‘아키텍처’를 함께 붙여 imagenet/resnet50:3c7039714 의 형식으로 모델 ID를 생성하도록 정책을 구성하였다. 이 방법은 생각 외로 collision 문제가 없고 깔끔했는데, 보통 코드에 버그가 없고 충분한 iteration을 돌린다면 같은 training args은 같은 accuracy의 모델로 수렴하기 때문이다.
1) Training args 바탕의 모델 비교
Machine Learning에서 training args는 모델을 기술description 할 수 있는 최고의 데이터이다. 논문을 통해 새롭게 제안된 아키텍처나 학습 기법training technique이 새로운 args로 들어가기도 하고, 반대로 args의 차이에 따른 성능 변화가 새로운 논문의 재료가 되기도 한다. 때문에 ML 모델의 관리를 도와주는 서비스에서는 다른 정보보다 training args에 대해 잘 보여주는 것이 가장 중요하다고 생각했고, 실제로 개발한 서비스에서도 모델의 training args를 중요한 데이터로 사용했다. Training args는 모델 ID를 생성하는데 사용되는 것 뿐만 아니라, 아래 비디오처럼 여러 모델 간 비교 시 args를 기반으로 diff를 보여주는 기능에서도 주요하게 이용되도록 개발을 진행했다.
해당 뷰를 통해 AI 연구자들이 서비스를 사용하며 “이 모델은 왜 올린 거지?”, “저 모델과 뭐가 다른거지?”에 대한 대답이 될 수 있게 하여 모델에 대한 정보를 기억하기 쉽게 함과 동시에, 모델을 올린 사람과 사용하는 사람이 다른 경우에 커뮤니케이션 비용을 낮출 수 있도록 기능을 개발하였다. 업로드된 모델은 웹 사이트에서 바로 다운로드하거나 CLICommand Line Interface를 통해서도 다운로드가 가능하며, 팀 내부적으로 사용하는 ML Code의 pipeline과도 연동되어 고유 모델 ID를 입력하면 바로 해당 모델로부터 학습을 이어서 진행하거나 transfer learning을 진행할 수도 있다.
2) Training args로 모델을 검색, 정렬
위의 기능에서는 소수 모델에 대해 args를 보고 비교해볼 수 있었다면, 다수의 모델 리스트에 대해서도 테이블 뷰를 통해 args로 검색과 정렬이 가능한 기능도 존재한다. Notion의 테이블을 써봤다면 익숙할법할 기능으로, 원하는 args에 대해 새로운 테이블 열로 프로젝션이 가능하며, 테이블에서의 정렬과 검색 모두 지원한다.
최근 Machine Learning에 사용되는 기술들이 정말 많아지고 있는 만큼, 한두 개의 필드만으로는 모델을 정확히 설명하기 어렵다고 생각한다. (hyperparameter가 여간 많아야지..) 그런 만큼 보다 유동적으로 검색에 대응하기 위하여 테이블에서 보고자 하는 필드를 상황에 맞게 바꿀 수 있도록 이 기능은 꼭 있어야 한다고 생각했고, 높은 우선순위로 작업을 진행하였다.
테이블에서 켜고 끌 수 있는 필드들은 hard-coding 되어있지 않고, 업로드된 모델의 args에 따라 dynamic 하게 불러오도록 개발을 진행하였다. 따라서 향후에 새로운 args가 추가되어도 대응 가능할 것으로 예상되며, 팀원 분들도 꽤 좋아하셨던 기능이다.
3) 모델 공유를 위한 기능
때로는 팀 내에서 연구용으로 만들었던 모델을 다른 팀이나 외부에 공유할 일이 있을 수 있다. 이 경우에 특정한 모델에 대해서 선택적으로 공유가 가능하며, Markdown으로 README를 작성할 수도 있게 개발을 진행했다.
모델 공유를 위해 위 기능 외에도 사용자마다 3단계의 권한(Admin, Read-only, Guest)으로 분리하여 권한을 나눌 수 있는 기능과, 모델에 대한 기본적인 관리 기능(모델 이름 변경, checkpoint 삭제, README 편집, public으로 전환) 또한 탑재하여 쉽게 서비스를 이용할 수 있도록 하였다.
정리
AI 연구 조직에서 모델은 일종의 자산이라고 할 수 있다. 그 자체만으로 가치를 지니진 않지만 잘 관리되지 못하면 추가적인 비용을 소모하게 하고 (비싼 GPU를 중복되는 모델 학습에 사용하는 것 자체만으로 손실이다), 잘 관리될 수 있다면 여러 조직 간에 시너지를 낼 수도 있다 (연구 조직에서의 pre-trained 모델을 서비스 조직에서 finetuning 하여 최종적으로 더 좋은 모델을 사용할 수 있게 된다).
물론 당장 내가 개발한 서비스가 전사적으로 사용되고 있는 것도 아니고, AI 연구자들의 생산성을 몇 배로 증가시키고 있다고도 하기 어렵다. 아마 이를 전사적으로 사용하기 위한 수준으로 바꾸기 위해서는 더 많은 리소스가 추가적으로 투입되어야 할 것이다. 하지만 연구 조직의 자산이라고 할 수 있는 모델이 앞으로 체계적으로 관리될 수 있도록 인사이트를 주었고, 또 실제로 관리로 인한 효과를 느껴볼 수 있는 서비스를 만들었다는 것에 의미가 있었다고 생각한다.
Task 2: 사내 ML Code 개발 참여
이번 단락에서는 내가 했던 일을 소개하기 앞서서, 내가 속해있었던 팀에 대해 간단히 소개하고자 한다. 해당 팀의 설립 취지는 이렇다. N사에는 vision 테스크를 풀고 있는 다양한 서비스와 팀이 존재하는데, 팀마다 서로 다른 codebase를 사용하고 있었다. 특히 최근 Computer Vision 분야에서는 정확도 향상을 위해 다양한 training technique이 제안되고 있으며 성능 향상을 위해서도 다양한 논문과 라이브러리가 나오고 있지만, 이들에 대한 업데이트를 각 팀마다 follow-up 하는 전체적으로 비효율적인 구조를 가지고 있었다.
이런 문제를 해결하기 위해 내가 인턴으로 있었던 팀에서는 사내에서 공통적으로 사용될 수 있는 Visual Backbone을 개발하고, 이를 전사에 공급하는 것을 목표로 하고 있었다. Backbone에는 정확도 및 성능 향상을 위한 자체적인 method/technique과 (이중 다수는 이후에 논문으로 공개된다), research 생산성 향상을 위해 반복 작업의 자동화 파이프라인까지 포함한다.
이중 내가 담당했던 부분은 엔지니어링 부분이다. 특히 개인적으로 1) 코드 품질 향상, 2) 생산성 향상, 3) 기술 부채 제거라는 목표를 세우고 크게 3가지의 작업을 진행했다.
 그림: Hidden Technical Debt in Machine Learning Systems, Sculley et al. NIPS 2015 에서 인용
그림: Hidden Technical Debt in Machine Learning Systems, Sculley et al. NIPS 2015 에서 인용
Machine Learning Code를 뒷받침하기 위해서는 많은 엔지니어링 작업이 필요하다.
1) 테스트 자동화 환경 구축
팀에서 개발하고 있는 Visual Backbone에는 이미 전부터 수많은 기능이 추가되고 있었지만, 오래된 기능에 대한 정상 동작을 보장해 주는 테스트 코드는 부재한 상황이었다. 하지만 ML 코드에 대한 테스트 자동화는 환경을 구축하는 것부터 쉽지 않았다. 우선 ML 코드에 대한 테스트는 일반적으로 오래 걸리기에 커밋 속도를 따라잡지 못하고, 또 GPU가 있어야만 돌아가는 코드도 많다.
이를 제대로 해결하기 위해서는 많은 비용이 추가적으로 발생할 것으로 예상됐는데, 예를 들면 모든 코드를 CPU에서도 돌아가게끔 호환성을 맞춰주는 작업과, 로직을 모듈 단위로 분리하여 최대한 빠르게 테스트가 가능한 구조로 변경하는 작업이 필요해보였다. 이를 짧은 인턴 기간 내에 이루는 것은 현실적으로 불가능해 보였고, 대신에 적당한 타협안으로 테스팅 환경을 구축하기로 하였다. 내가 생각한 정책은 아래와 같다:
- 유닛 테스트와 통합 테스트의 분리
- 유닛 테스트는 CPU로 매 commit마다 수행
- 통합 테스트는 GPU로 매일 새벽마다 master branch에서만 수행
특히 통합 테스트의 경우에는 테스트 통과 여부뿐만 아니라 speed, accuracy 등도 함께 기록하도록 구성하여 특정 commit 이후로 정확도가 튄다거나 속도가 급격히 느려지는 상황을 트래킹 할 수 있는 구조로 만들었다.
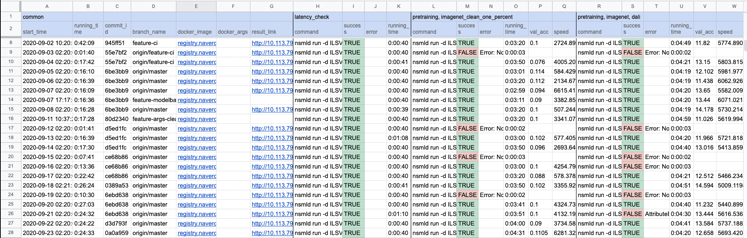 통합 테스트 결과가 기록되는 스프레드시트
통합 테스트 결과가 기록되는 스프레드시트
테스트에 대한 결과는 사내 Git 저장소와 연동되어 결과를 실시간으로 볼 수 있게 구성하였다. 자동화 테스트 환경을 구축하기 전에는 테스트를 위한 스크립트는 존재했지만 실제로 실행해보면 잘 되지 않았던 옵션들이 많았는데, 환경 구축 이후로는 확실히 이전 기능에 대한 보장이 이루질 수 있게 되었다.
2) 도커 이미지 cleanup
N사의 AI 연구 조직에서도 Docker는 적극적으로 이용되고 있다. 다수의 GPU를 사용하기 위해서는 사내 서비스를 이용하여야 하는데, 이 사내 서비스가 Docker 위에서 코드를 실행하는 구조로 되어있기 때문이다. 문제는 Visual Backbone에서 학습 속도 향상 등을 위해 외부 라이브러리 업데이트(e.g., Nvidia Dali)에 빠르게 대응하고 있었지만, Docker가 병목이 되는 경우가 많았다는 점이다.
존재하던 문제로는 우선 이미지 빌드에 많은 시간 걸렸고(최종 이미지 10GB), 새로운 이미지를 사내 서비스에서 돌릴 때도 많은 시간이 소요되었다. (machine에서 새롭게 10GB의 이미지를 pull 하는 시간). 또한 Docker 이미지마다 성능이 다른 문제가 종종 발생하였으나 디버깅이 난해하다는 문제도 존재하였다. 이를 해결하고자 아래와 같은 작업을 진행했다.
- 기존 10GB에 달하는 Docker image를 4GB대로 경량화 (불필요한 라이브러리 제거)
- Layer 수 최소화, 명령어의 arrangement 조정을 통해 빌드 시간 단축
- Vim, matplolib 등 학습 시에는 필요 없지만 디버깅 시 유용한 라이브러리를 담은 이미지 분리
- Base image는 용량을 최소화하고, 디버깅용 이미지는 base를 상속받도록 구성
3) 코드 로직 cleanup
위 작업들 이외에도 pretrained model 저장 및 관리 서비스를 만들며 Visual Backbone의 weights save/load 파이프라인을 정리하는 작업을 진행하였고, 또 전체 코드에 PyLint를 적용하며 anti-pattern을 다수 제거하는 작업과 training args를 immutable 하게 변경하는 등 data flow 일부 개선도 진행하였다.
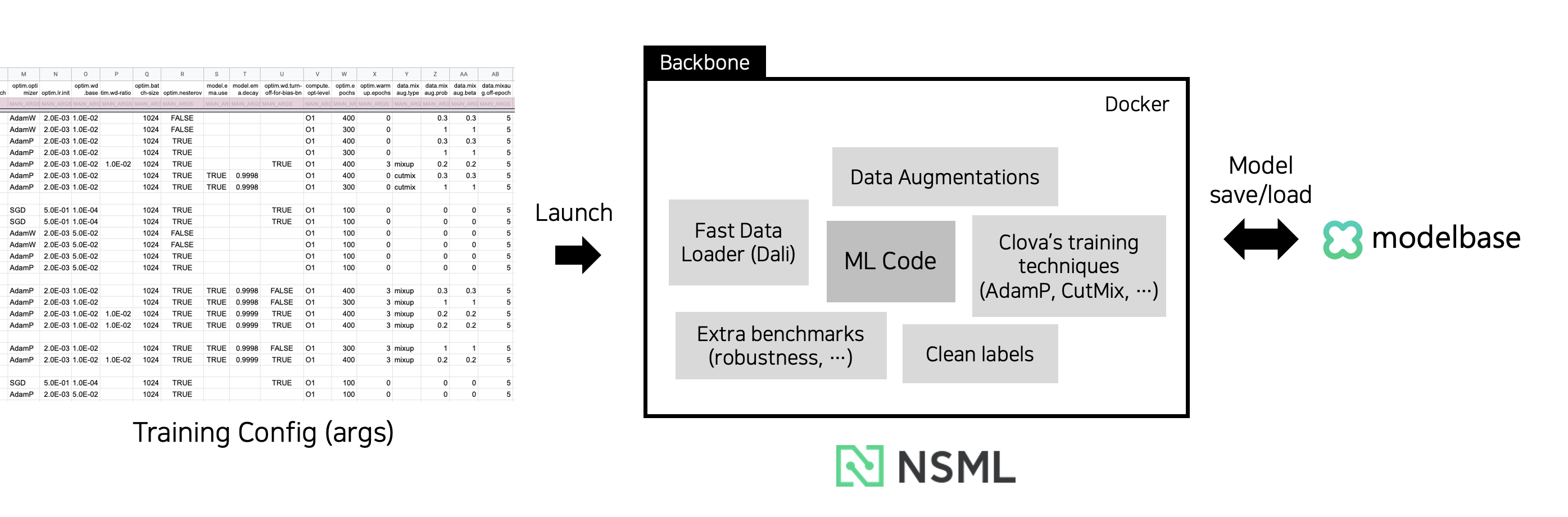 인턴 기간이 끝나갈 때쯤의 ML 코드 파이프라인. 연구 생산성을 위한 다양한 기법들을 경험할 수 있었고, 일부 파이프라인의 개발에도 어느 정도 기여할 수 있었다.
인턴 기간이 끝나갈 때쯤의 ML 코드 파이프라인. 연구 생산성을 위한 다양한 기법들을 경험할 수 있었고, 일부 파이프라인의 개발에도 어느 정도 기여할 수 있었다.
정리
결과적으로 3가지 작업을 하며, 작은 부분이지만 처음 목표로 세웠던 키워드들을 달성했다고 생각하고 있다.
- 테스트 자동화 환경 구축 → 코드 품질 향상
- 도커 이미지 cleanup → 생산성 향상
- 코드 로직 cleanup → 기술 부채 제거
특히 인턴 동안 처음으로 PyTorch를 사용해보았고 또 수만 줄 이상의 ML 코드를 만져본 것 또한 처음이었는데, 나름 빠르게 코드에 적응하고 기여를 한 것 같아 만족스러운 작업이었다. 더불어 직접적인 코드 수정 이외에도 향후 코드 품질을 지속적으로 관리할 수 있게 하는 틀을 처음 만들었는데, 이점에서 추가적인 Contribution Point가 있었다고 생각하고 있다.
Task 3: 엔지니어링 중심의 개인 연구 주제 진행
마지막으로 인턴 기간 중 약 2주는 인턴 기간 전부터 갖고 있던 개인 연구 주제를 N사의 리소스를 사용하여 검증하고 발전시켜 나가는 작업을 진행했다. 팀에서 요청한 것은 아니었지만 짧은 기간이라도 국내 최고의 연구자/리소스가 있는 곳에서 연구를 진행해보는 것이 향후에 큰 도움이 될 것이라는 개인적인 생각으로 시작하게 되었다.
다만 아직까지 진행 중인 연구이기에 아이디어에 대해서 공개를 할 수는 없지만, 아주 간단하게만 소개를 하자면 머신 러닝 모델을 사용자에게 serving 할 때의 새로운 방법을 제안하는 주제이다. 팀원분들께 괜찮은 평가를 받았고, 또 엔지니어링과 관련해서 challenge가 많은 재미있는 주제라고 생각하고 있다. 이 주제는 팀원분들께 계속 피드백을 받으며 진행 예정이고, 이후 논문으로 공개가 된다면 글에서도 다뤄보고자 한다.
 다양한 논문이 공개되는 학회의 모습. 글과는 무관하다.
다양한 논문이 공개되는 학회의 모습. 글과는 무관하다.
결론 및 후기
인턴을 하면서 진행했던 3가지 작업에 걸쳐 소개를 했었는데, 각 작업에 대한 성과를 요약하자면 아래처럼 쓸 수 있을 것 같다.
- Task 1: AI 연구자를 위한 사내 Web Service 개발 → 작은 규모지만 온전한 사내 서비스 개발 완료
- Task 2: 사내 ML Code 개발 참여 → 작지만 팀에서 필요로 했던 작업들 처리 완료
- Task 3: 엔지니어링 중심의 개인 연구 주제 진행 → 자신만의 아이디어를 공유하고 발전시킬 수 있었던 기회
정리를 하고 보니 3개월이라는 짧은 시간 동안 꽤 많은 것들을 한 것 같은데, 이는 처음부터 어떤 것들을 할지에 대한 충분한 고민이 있었기에 가능했던 것이라고 생각한다. 특히 계획을 세우는 과정 중에 여러 회사의 career 페이지에서 Research Software Engineer, 혹은 AI Software Engineer의 업무를 찾아보고 그중 할 수 있는 일들을 찾아보기까지 하면서 내가 할 수 있는 것들이 무엇인지를 찾는데 많은 시간을 투자했었다.
그 결과 다양한 작업들을 진행하며 Computer Vision 분야에 대한 기본적인 이해와 AI Research Scientist 들이 일하는 방식을 배울 수 있었고, 또 AI 연구 분야에서도 해볼 만한 engineering task가 정말 많다는 것을 느낄 수 있었다. 하지만 무엇보다 값졌던 경험은 조직에 능동적으로 기여하고자 하는 태도와 그에 따른 결과라고 생각하는데, 누가 시키지 않아도 팀에 도움이 될만한 일들이 무엇이 있을지 지속적인 고민을 했었고, 또 해보고자 하는 것들을 적극 시도했기에 이런 결과를 낼 수 있었다고 생각한다.